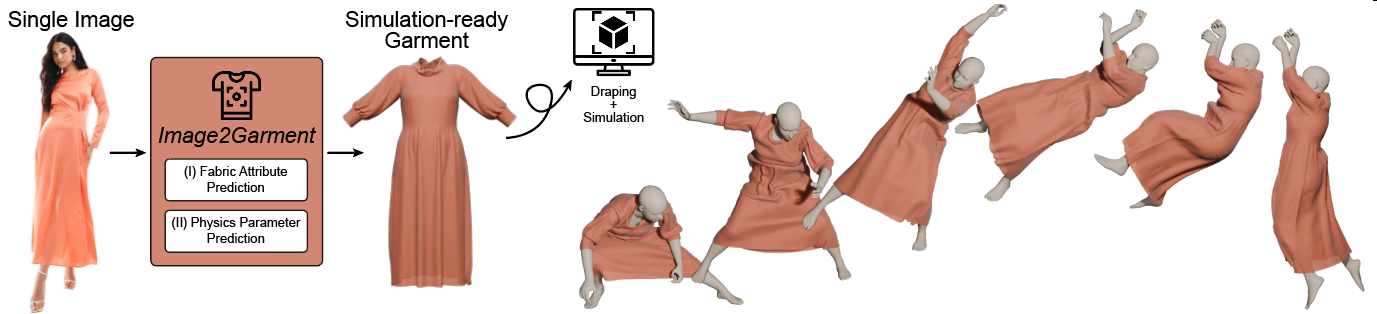
Estimating physically accurate, simulation-ready garments from a single image is challenging due to the
absence of image-to-physics datasets and the ill-posed nature of this problem. Prior methods either
require multi-view capture and expensive differentiable simulation or predict only
garment geometry without the material properties required for realistic simulation.
We propose a feed-forward framework that sidesteps these limitations by first fine-tuning a
vision–language model to infer material composition and fabric attributes from real images, and then
training a light-weight predictor that maps these attributes to the corresponding physical fabric
parameters using a small dataset of material–physics measurements.
Our approach introduces two new datasets (FTAG and T2P) and delivers simulation-ready garments from a
single image without iterative optimization. Experiments show that our estimator achieves superior
accuracy in material composition estimation and fabric attribute prediction, and by passing them through
our physics parameter estimator, we further achieve higher fidelity simulations compared to
state-of-the-art image-to-garment methods.